KIÊN THỨC, SEARCH ENGINE OPTIMIZATON (SEO)
Robots.txt và SEO: Mọi thứ mà bạn cần phải biết

Th3
Nội dung chính
CÓ THỂ BẠN QUAN TÂM

Thiết kế Website trọn gói 2,900,000đ

Quảng cáo Google

Quảng cáo Facebook

Chăm sóc Website

Chăm sóc Fanapge

Thiết kế Mobile App

Quảng cáo Tiktok
CÓ THỂ BẠN QUAN TÂM
Thiết kế Website trọn gói 2,900,000đ
Quảng cáo Google
Quảng cáo Facebook
Chăm sóc Website
Chăm sóc Fanapge
Thiết kế Mobile App
Quảng cáo Tiktok
Robots.txt là một trong những file đơn giản nhất trên website, nhưng đồng thời, nó cũng lại là một trong những thứ dễ gây rối nhất. Chỉ cần một ký tự bị thiếu là có thể phá đi thành quả SEO của bạn rồi. Hơn nữa, nó còn ngăn cả các công cụ tìm kiếm truy cập nội dung quan trọng trên site đó.
Đây là lý do tại sao mà việc các cấu hình trong robots.txt bị sai lại cực kỳ phổ biến – ngay cả những người có kinh nghiệm làm SEO cũng vẫn còn mắc phải.
File robots.txt là gì?
Một file robots.txt sẽ cho các công cụ tìm kiếm biết nơi mà chúng có thể và không thể đi được trên site của bạn.
Chủ yếu là, nó sẽ liệt kê tất cả nội dung mà bạn muốn chặn đối với những bộ máy như Google. Bạn cũng có thể cho một vài trong số chúng (không phải Google) biết được nên thu thập những nội dung mình cho phép như thế nào.
LƯU Ý QUAN TRỌNG
Hầu hết các công cụ tìm kiếm đều rất tuân thủ. Họ không có thói quen phá đi 1 điều gì mới. Tuy nhiên, 1 số lại không hề “ngần ngại” những lệnh chặn này.
Google không như thế. Họ tuân theo các hướng dẫn trong tệp robots.txt.
Bạn chỉ cần biết rằng 1 vài search engine lại hoàn toàn bỏ qua nó.
Robots.txt trông như thế nào?
Sau đây là dạng cơ bản của 1 file robots.txt:

Nếu bạn chưa từng thấy một trong những tập tin này trước đây thì nó sẽ trông có vẻ hơi khó nhằn. Tuy nhiên, cú pháp khá đơn giản. Nói tóm lại, bạn đặt ra quy tắc cho các bot bằng cách ghi tên user-agent của chúng rồi theo sau đó là các chỉ thị.
Hãy cùng tìm hiểu về hai phần này cụ thể hơn.
User-agent
Mỗi 1 bộ máy tìm kiếm tự định danh cho nó bằng một user-agent khác nhau. Bạn có thể đặt các chỉ dẫn tùy chỉnh với từng công cụ trong tệp robots.txt của mình. Có hàng trăm user-agent, nhưng sau đây là một số cái tên chuyên dùng cho SEO:
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
CHÚ Ý BÊN LỀ. Mọi user-agent đều phân biệt chữ hoa và thường trong robots.txt
Bạn cũng có thể sử dụng ký tự sao (*) để gán chỉ thị cho tất cả chúng.
Ví dụ: bạn muốn chặn hết các bot (trừ Googlebot) thu thập dữ liệu site của mình. Và đây là cách mà bạn sẽ làm:

File robots.txt có thể bao gồm các lệnh cho bất cứ user-agent nào mà bạn muốn. Nhưng mỗi khi khai báo 1 user-agent mới, bạn sẽ phải đặt lệnh lại từ đầu một lần nữa. Nói cách khác, nếu bạn thêm nhiều lệnh, chúng sẽ chỉ được áp dụng với bot đầu tiên mà không phải bot thứ hai, thứ ba hay thứ tư, v.v.
Trừ khi bạn khai báo cùng 1 user-agent nhiều lần. Trong trường hợp này, tất cả các lệnh có liên quan sẽ được kết hợp lại và làm theo.
LƯU Ý QUAN TRỌNG
Con bọ chỉ tuân lệnh các chỉ thị được khai báo dưới (những) user-agent được đặt chính xác nhất cho chúng. Đó là lý do tại sao tệp robots.txt ở trên chặn tất cả các bot thu thập dữ liệu (trừ Googlebot và các bot Google khác). Googlebot sẽ bỏ qua khai báo không rõ ràng.
Chỉ thị
Đây là các quy tắc mà bạn muốn user-agent phải tuân theo.
Chỉ thị được hỗ trợ
Sau đây là các chỉ thị mà Google hiện đang hỗ trợ, kèm theo cách dùng của chúng.
Disallow
Sử dụng lệnh này để chỉ thị công cụ tìm kiếm không được phép vào các file và trang web tại một đường dẫn cụ thể. Ví dụ: nếu bạn muốn chặn mọi công cụ truy cập blog và tất cả các bài viết của mình trên đó, tệp robots.txt của bạn có thể là như thế này:

CHÚ Ý BÊN LỀ. Nếu bạn không xác định được đường dẫn để điền sau lệnh disallow, công cụ tìm kiếm sẽ bỏ qua nó.
Allow
Sử dụng lệnh này để cho phép các search engine thu thập dữ liệu thư mục con hoặc từ trang – ngay cả trong 1 thư mục không được phép. Ví dụ: nếu bạn muốn ngăn toàn bộ công cụ truy cập vào mọi bài đăng trên blog của mình ngoại trừ một bài, thì file robots.txt có thể trông như thế này:

Ở ví dụ này, bộ máy tìm kiếm có thể truy cập /blog/allowed-post. Nhưng họ không thể truy cập:
/blog/another-post (bài khác)
/blog/yet-another-post (1 bài khác nữa)
/blog/download-me.pdf
Cả Google và Bing đều hỗ trợ chỉ thị này.
CHÚ Ý BÊN LỀ. Cũng như disallow, nếu bạn không xác định được đường dẫn sau lệnh allow, công cụ tìm kiếm sẽ bỏ qua nó.
Lưu ý các lệnh bị xung đột
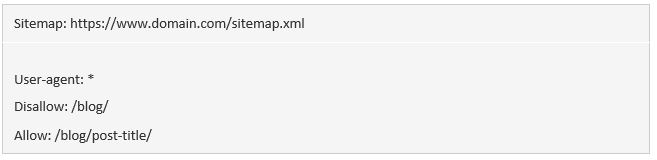
Nếu bạn không cẩn thận, lệnh allow và disallow có thể dễ bị xung đột với nhau. Trong ví dụ dưới đây, chúng ta không cho phép truy cập /blog/ nhưng cho phép truy cập /blog.

Trong trường hợp này, URL /blog/post-title/ dường như không được và được cho phép cùng lúc. Vậy rốt cuộc thì lệnh nào mới có tác dụng?
Đối với Google và Bing, quy luật là: chỉ thị nào có nhiều ký tự nhất thì sẽ có hiệu lực. Ở đây, đó là lệnh disallow.
Disallow: /blog/ (6 ký tự)
Allow: /blog (5 ký tự)
Nếu 2 lệnh có độ dài bằng nhau, thì lệnh ít hạn chế nhất sẽ được áp dụng. Trong trường hợp ấy, đó sẽ là lệnh allow.
CHÚ Ý BÊN LỀ. Ở đây, /blog (không có dấu gạch chéo sau cùng) vẫn có thể được truy cập và thu thập dữ liệu.
Quan trọng là, đây chỉ là trường hợp của Google và Bing. Còn các bộ máy tìm kiếm khác sẽ làm theo chỉ thị khớp đầu tiên. Lúc này, lệnh disallow sẽ có hiệu lực.
Sitemap
Sử dụng lệnh này để nêu rõ vị trí (các) sitemap của bạn với công cụ tìm kiếm. Nếu không biết nhiều về sitemap, bạn có thể hiểu rằng chúng sẽ bao gồm các trang mà bạn muốn search engine thu thập dữ liệu và lập chỉ mục.
Sau đây là ví dụ về 1 file robots.txt bằng chỉ thị sitemap:
Việc có (các) sitemap trong tệp robots.txt quan trọng như thế nào? Nếu bạn đã submit qua Search Console, thì đó sẽ là điều dư thừa với Google. Tuy nhiên, nó vẫn cho các bộ máy tìm kiếm biết nơi để tìm sitemap của bạn, nên nó vẫn có tác dụng.
Cần để ý rằng bạn sẽ không cần phải lặp lại chỉ thị sitemap nhiều lần đối với từng user-agent nữa. Lệnh này không chỉ áp dụng cho duy nhất 1 bot. Do vậy, bạn nên đặt nó ngay đầu hoặc cuối file robots.txt. Ví dụ:
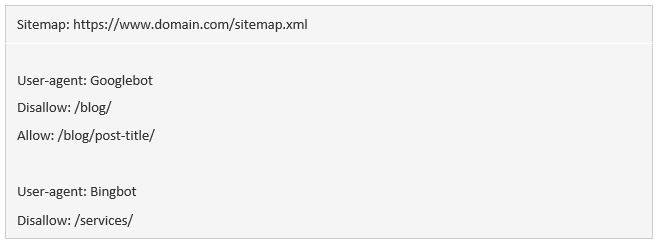
Google hỗ trợ chỉ thị sitemap, cũng như Ask, Bing, và Yahoo.
CHÚ Ý BÊN LỀ. Bạn có thể để nhiều sitemap mà bạn muốn trong file robots.txt.
Chỉ thị không được hỗ trợ
Những chỉ thị dưới đây không còn được Google hỗ trợ nữa – chính xác thì, 1 số lệnh còn chưa bao giờ được hỗ trợ.
Crawl-delay
Trước đây, bạn có thể sử dụng lệnh này để chỉ định thời gian trước mỗi lần bot thu thập dữ liệu. Ví dụ, nếu bạn muốn Googlebot đợi 5 giây trước khi crawl tiếp, bạn sẽ đặt lệnh là 5 như thế này:

Google không còn hỗ trợ lệnh này nữa, nhưng Bing và Yandex thì vẫn.
Điều này cho thấy, bạn cần cẩn thận với lệnh này, đặc biệt là nếu bạn có 1 site lớn. Khi đặt 1 lệnh crawl-delay 5 giây, thì tức là bạn đang hạn chế các bot crawl với nhiều nhất là 17,280 URLs 1 ngày. Nó sẽ không có ích nếu bạn có vài triệu trang, nhưng bạn vẫn có thể tiết kiệm được băng thông khi có 1 website nhỏ.
Noindex
Lệnh này chính thức chưa bao giờ được Google hỗ trợ. Tuy nhiên, mãi cho đến gần đây, Google được cho là có 1 vài “code có thể xử lý được các quy tắc được và không được hỗ trợ (ví dụ noindex)”. Vậy nếu muốn ngăn Google lập chỉ mục tất cả các bài trên blog, bạn có thể sử dụng lệnh sau:

Tuy nhiên, vào 01/09/2019, Google đã nói rõ lệnh này không hề được hỗ trợ. Nếu bạn muốn chặn 1 trang hoặc file khỏi các search engine, hãy thay thế bằng cách sử dụng thẻ meta robots hoặc x-robots HTTP header.
Nofollow
Đây là 1 chỉ thị khác mà Google hoàn toàn không hỗ trợ, và được dùng để chỉ định bộ máy tìm kiếm không được đi theo các link trên những trang và file ở 1 đường dẫn cụ thể. Ví dụ, nếu không muốn cho Google crawl tất cả link trên blog, bạn có thể dùng lệnh sau:

Google đã tuyên bố rõ rằng lệnh này không được hỗ trợ vào ngày 01/09/2019. Nếu bây giờ bạn muốn đặt lệnh nofollow mọi link trên 1 trang, bạn nên sử dụng thẻ meta hoặc x-robots header. Nếu muốn Google không đi theo những link cụ thể trên 1 trang, dùng thuộc tính rel=”nofollow”.
Liệu bạn có cần tới file robots.txt?
Việc có 1 file robots.txt sẽ không quan trọng lắm đối với nhiều website, đặc biệt là những web nhỏ.
Nhưng không có gì là không tốt nếu có 1 tệp. Nó giúp bạn kiểm soát được nơi các search engine có thể và không thể đi được trên website của mình, và điều đó có thể giúp:
- Ngăn trình việc thu thập dữ liệu nội dung trùng lặp;
- Giữ kín các phần của website (ví dụ: staging site của bạn);
- Chặn việc thu thập dữ liệu của các trang kết quả tìm kiếm nội bộ;
- Ngăn máy chủ bị quá tải;
- Đề phòng Google khỏi bị lãng phí “crawl budget” (tài nguyên để thu thập dữ liệu).
- Ngăn chặn các tập tin hình ảnh, video và tài nguyên xuất hiện trong kết quả tìm kiếm của Google.
Lưu ý rằng mặc dù Google thường không index các trang web bị chặn trong robots.txt, nhưng không có cách nào sẽ đảm bảo được việc loại những trang đó khỏi kết quả tìm kiếm bằng tệp này.
Giống như Google cho biết, nếu content được liên kết từ các nơi khác trên web, nó vẫn có thể xuất hiện trong kết quả tìm kiếm của Google.
Cách để tìm file robots.txt của bạn
Nếu bạn đã có tệp robots.txt trên website của mình, nó sẽ có thể truy cập được tại domain.com/robots.txt. Điều hướng đến URL trong trình duyệt của bạn. Nếu bạn thấy một cái gì đó như thế này, thì nghĩa là bạn có tệp robots.txt:

Làm thế nào để tạo tệp robots.txt
Nếu bạn chưa có file robots.txt thì đừng lo, bởi cách tạo rất dễ. Chỉ cần mở một tài liệu trống .txt và bắt đầu nhập các chỉ thị. Ví dụ: nếu bạn không cho phép tất cả các công cụ tìm kiếm thu thập dữ liệu thư mục /admin/của bạn, nó sẽ trông giống như thế này:

Tiếp tục xây dựng các lệnh cho đến khi bạn thấy ổn với những gì mình có. Lưu tệp của bạn dưới dạng “robots.txt”.
Ngoài ra, bạn cũng có thể tạo robots.txt qua công cụ này.
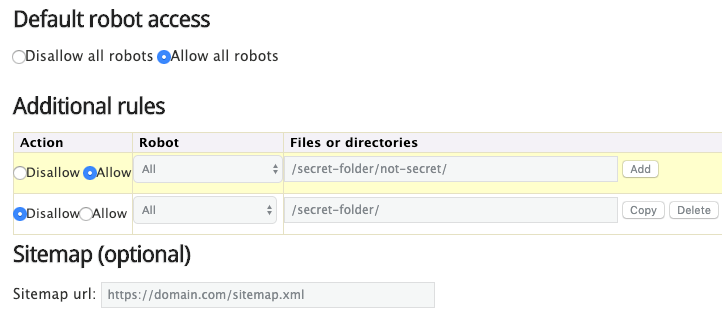
Ưu điểm của nó là giảm thiểu được các lỗi cú pháp. Điều này khá là tốt vì một sai lầm sẽ có thể dẫn đến việc SEO trang web của bạn bị hủy hoại.
Còn nhược điểm là chúng sẽ có phần hạn chế về khả năng tùy chỉnh.
Nơi để file robots.txt của bạn
Hãy đặt tệp robots.txt của bạn trong thư mục gốc của tên miền phụ. Ví dụ: để kiểm soát trình crawl trên domain.com, tệp này nên được truy cập tại domain.com/robots.txt.
Nếu bạn muốn kiểm soát việc thu thập thông tin trên một tên miền phụ như blog.domain.com, thì nó nên được truy cập tại blog.domain.com/robots.txt.
Cần kiểm tra các lỗi của 1 trang cụ thể?
Dán URL vào công cụ Google’s URL Inspection trong Search Console. Nếu nó bị chặn bởi robots.txt, bạn sẽ thấy một cái gì đó giống thế này:
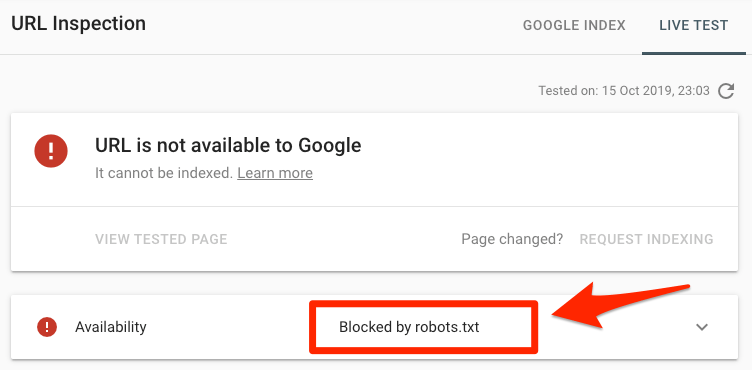
URL đã submit bị chặn bởi robots.txt
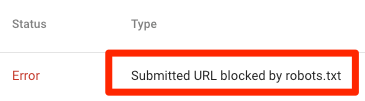
Ít nhất một trong số các URL ở (các) sitemap đã submit của bạn bị chặn trong tệp robots.txt.
Nếu bạn đã tạo đúng sơ đồ trang web của mình và loại trừ các trang gắn thẻ canonical, noindex, và redirect, thì sẽ không có trang đã submit nào bị chặn bởi robots.txt. Nếu có, hãy tìm hiểu các trang có vấn đề, sau đó điều chỉnh tệp robots.txt của bạn để loại bỏ những lỗi đó.
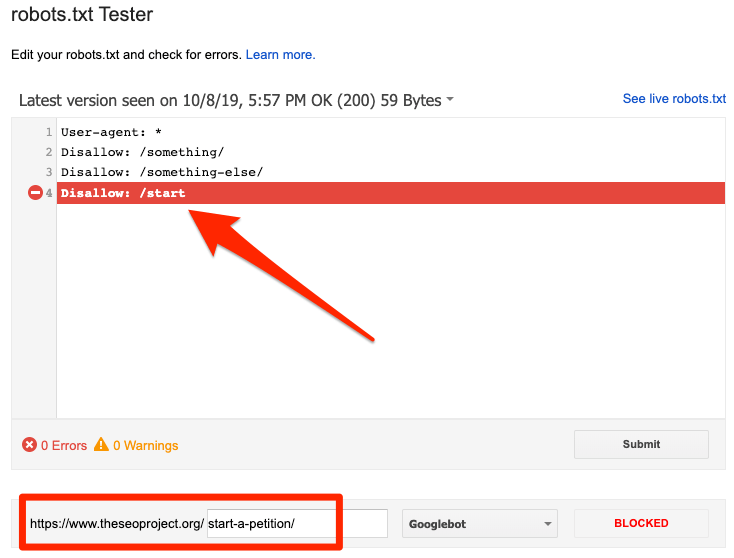
Bạn có thể sử dụng trình kiểm tra robots.txt của Google để xem lệnh nào đang chặn nội dung. Hãy cẩn thận khi thực hiện quá trình này. Bạn sẽ rất dễ bị mắc lỗi và từ đó có thể làm ảnh hưởng các trang và file khác nữa.
Bị chặn bởi robots.txt
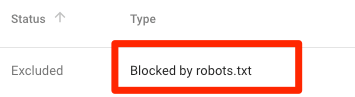
Như thế này tức là bạn có nội dung bị chặn bởi robots.txt nên hiện đang không được Google index.
Nếu nội dung ấy quan trọng và cần được lập chỉ mục, hãy xóa lệnh chặn crawl trong tệp robots.txt. (Sẽ tốt hơn nếu đảm bảo rằng nội dung được index). Nếu bạn đã chặn nội dung trong file này với mục đích loại nó khỏi chỉ mục của Google, hãy xóa lệnh đó và sử dụng thẻ meta robots hoặc x-robots-header thay thế. Đây là cách duy nhất để đảm bảo không cho Google index content.
CHÚ Ý BÊN LỀ. Việc xóa lệnh chặn khi cố gắng loại trừ một trang khỏi kết quả tìm kiếm là rất quan trọng. Nếu thất bại, và Google không thấy thẻ noindex hoặc HTTP header – nội dung vẫn sẽ được lập chỉ mục.
Vẫn bị index, dù đã chặn trong robots.txt
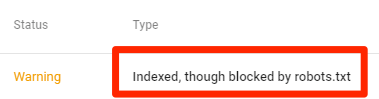
Như vậy nghĩa là một số nội dung dù bị chặn bởi file robots.txt vẫn được lập chỉ mục trong Google.
Một lần nữa, nếu bạn đang cố gắng loại trừ nó khỏi kết quả tìm kiếm của Google, thì tệp robots.txt sẽ không phải là 1 giải pháp. Xóa lệnh chặn crawl và thay vào đó sử dụng thẻ meta robots hoặc HTTP header x-robots-tag để ngăn index.
Nếu bạn vô tình chặn nó và muốn giữ trong chỉ mục Google, hãy xóa lệnh chặn trong tệp robots.txt. Điều này có thể giúp cải thiện khả năng hiển thị của nội dung trong trang tìm kiếm của Google.
Câu hỏi thường gặp
Dưới đây là một vài câu hỏi thường gặp mà chưa có trong bài hướng dẫn trên của chúng tôi. Hãy comment cho chúng tôi biết nếu thiếu bất cứ điều gì để tiếp tục cập nhật bổ sung.
Dung lượng tối đa của một tập tin robots.txt là bao nhiêu?
(Khoảng) 500 kilobyte.
Robots.txt ở đâu trong WordPress?
Cùng 1 chỗ: domain.com/robots.txt.
Làm cách nào để chỉnh sửa robots.txt trong WordPress?
Bạn có thể chỉnh thủ công hoặc sử dụng một trong những plugin SEO của WordPress như Yoast cho phép bạn sửa robots.txt từ WordPress backend.
Điều gì xảy ra nếu tôi không cho phép truy cập vào nội dung noindex trong tệp robots.txt?
Google sẽ không bao giờ thấy lệnh noindex bởi nó không thể thu thập dữ liệu của trang đó.
https://twitter.com/methode?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E829952819373494272&ref_url=https%3A%2F%2Fahrefs.com%2Fblog%2Frobots-txt%2F
Kết luận cuối
Robots.txt tuy chỉ là một file đơn giản nhưng lại có 1 tầm quan trọng nhất định. Nếu sử dụng một cách khôn ngoan, nó sẽ đem tới tác động tích cực cho quá trình SEO của bạn. Còn nếu không cẩn thận, bạn sẽ phải hối tiếc.

CÔNG TY TNHH HBMEDIA - HBMEDIA CO.,LTD
Trụ sở: 242/8D Bà Hom -Phường 13, Quận 6 - Hồ Chí Minh
VPĐD : 151/67D Liên khu 4-5, Bình Hưng Hòa B, Bình Tân, Tp.HCM
Tư vấn dịch vụ : 0933 576 079
Từ 8h00 – 18h00 các ngày từ thứ 2 đến thứ 7



